概要
特徴
- 階層的フレーズ構造の分析支援
- フレーズ構成音の頂点らしさ分析支援
- フレーズ単位でのインタラクティブ表情付け支援
News release
- (9/13) CrestMuseシンポジウム 2010 でデモンストレーションを行いました。
Mixtract による演奏表情付けの流れ
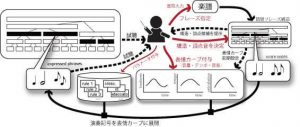
【動画解説|システムを使った表情付け手順】
- まずは楽譜を開き,単純に聞いてみています。
- メロディの一部分をドラッグし,「フレーズ」を指定していきます。
ある程度入力が進むと,自動的に上下の階層のフレーズが生成されます(この 動画では上の階層のみ生成しています)。 - 最初のフレーズをダブルクリックすると別画面が現れます。
画面の下側は,演奏表情を書き込むところです。まずは強弱を,次にテンポを手書きで入れてみます。 - 聴いてみると何やらヘンです。ということで,演奏表情を修正してみます。
- 他のフレーズについても同様に,演奏表情を入れてみます。
- 上の階層のフレーズについても同じように演奏表情(強弱)をつけてみます。メイン画面にある楽曲全体の強弱カーブ(ふたこぶの山)に注目してみてください。下の階層のフレーズふたつに与えた強弱カーブが,形を残したまま反映されているのが見えます。
- 同様にテンポカーブも入れておきます。
- ちなみに,指定した長さの範囲で和声記号を入力できるようになっています。
- このようにして,それぞれのフレーズの長さに合わせた演奏表情を入力して行くことで,楽曲全体のフレーズ表現ができあがっていきます。この事例でのとりあえず完成版をお聴きください。
(おわり)
参考文献
5289163
Mixtract
ieee
50
date
desc
title
1185
https://m-use.net/wp-content/plugins/zotpress/
%7B%22status%22%3A%22success%22%2C%22updateneeded%22%3Afalse%2C%22instance%22%3A%22zotpress-3bbf090f103c773db95ff6d4d3fc6732%22%2C%22meta%22%3A%7B%22request_last%22%3A0%2C%22request_next%22%3A0%2C%22used_cache%22%3Atrue%7D%2C%22data%22%3A%5B%7B%22key%22%3A%22QFCCI5J7%22%2C%22library%22%3A%7B%22id%22%3A5289163%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Hashida%20et%20al.%22%2C%22parsedDate%22%3A%222010%22%2C%22numChildren%22%3A0%7D%2C%22bib%22%3A%22%3Cdiv%20class%3D%5C%22csl-bib-body%5C%22%20style%3D%5C%22line-height%3A%201.35%3B%20%5C%22%3E%5Cn%20%20%3Cdiv%20class%3D%5C%22csl-entry%5C%22%20style%3D%5C%22clear%3A%20left%3B%20%5C%22%3E%5Cn%20%20%20%20%3Cdiv%20class%3D%5C%22csl-left-margin%5C%22%20style%3D%5C%22float%3A%20left%3B%20padding-right%3A%200.5em%3B%20text-align%3A%20right%3B%20width%3A%201em%3B%5C%22%3E%5B1%5D%3C%5C%2Fdiv%3E%3Cdiv%20class%3D%5C%22csl-right-inline%5C%22%20style%3D%5C%22margin%3A%200%20.4em%200%201.5em%3B%5C%22%3EM.%20Hashida%2C%20S.%20Tanaka%2C%20T.%20Baba%2C%20and%20H.%20Katayose%2C%20%26%23x201C%3BMixtract%3A%20An%20Environment%20Designing%20Musical%20Phrase%20Expression%2C%26%23x201D%3B%20in%20%3Ci%3EProceedings%20of%20Sound%20and%20Music%20Computing%20%28SMC%29%202010%3C%5C%2Fi%3E%2C%202010%2C%20pp.%2021%26%23x2013%3B24.%3C%5C%2Fdiv%3E%5Cn%20%20%3C%5C%2Fdiv%3E%5Cn%3C%5C%2Fdiv%3E%22%2C%22data%22%3A%7B%22itemType%22%3A%22conferencePaper%22%2C%22title%22%3A%22Mixtract%3A%20An%20Environment%20Designing%20Musical%20Phrase%20Expression%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Mitsuyo%22%2C%22lastName%22%3A%22Hashida%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Shunji%22%2C%22lastName%22%3A%22Tanaka%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Takashi%22%2C%22lastName%22%3A%22Baba%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Haruhiro%22%2C%22lastName%22%3A%22Katayose%22%7D%5D%2C%22abstractNote%22%3A%22Music%20performance%20is%20processing%20to%20embody%20musical%20ideas%20in%20concrete%20sound%2C%20giving%20expression%20to%20tempo%20and%20dynamics%20and%20articulation%20to%20each%20note.%20Human%20competence%20in%20music%20performance%20rendering%20is%20enhanced%20and%20fostered%20by%20supplementing%20a%20lack%20of%20performance%20skill%20and%20musical%20knowledge%20using%20computers.%20This%20paper%20introduces%20a%20performance%20design%20environment%20called%20Mixtract%2C%20which%20assists%20users%20in%20designing%20%5Cu201cphrasing%2C%5Cu201d%20and%20a%20performance%20design%20guideline%20called%20the%20HoshinaMixtract%20method%20executable%20on%20Mixtract.%20Mixtract%20provides%20its%20users%20with%20a%20function%20for%20assisting%20in%20the%20analysis%20of%20phrase%20structure%20and%20a%20function%20to%20show%20the%20degree%20of%20importance%20of%20each%20note%20in%20a%20phrase%20group.%20We%20verified%20that%20the%20proposed%20system%20and%20method%20help%20seven%20children%20to%20externalize%20their%20musical%20thought%20and%20help%20them%20transform%20their%20subjective%20musical%20thoughts%20into%20objective%20ones.%22%2C%22proceedingsTitle%22%3A%22Proceedings%20of%20Sound%20and%20Music%20Computing%20%28SMC%29%202010%22%2C%22conferenceName%22%3A%22%22%2C%22date%22%3A%222010%22%2C%22eventPlace%22%3A%22%22%2C%22DOI%22%3A%22%22%2C%22ISBN%22%3A%22%22%2C%22citationKey%22%3A%22%22%2C%22url%22%3A%22%22%2C%22ISSN%22%3A%22%22%2C%22language%22%3A%22%22%2C%22collections%22%3A%5B%2286JQZ5DR%22%2C%223W3TMNBQ%22%5D%2C%22dateModified%22%3A%222019-04-20T11%3A11%3A42Z%22%7D%7D%2C%7B%22key%22%3A%22DV42PJ7P%22%2C%22library%22%3A%7B%22id%22%3A5289163%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Hashida%20et%20al.%22%2C%22parsedDate%22%3A%222009-09%22%2C%22numChildren%22%3A1%7D%2C%22bib%22%3A%22%3Cdiv%20class%3D%5C%22csl-bib-body%5C%22%20style%3D%5C%22line-height%3A%201.35%3B%20%5C%22%3E%5Cn%20%20%3Cdiv%20class%3D%5C%22csl-entry%5C%22%20style%3D%5C%22clear%3A%20left%3B%20%5C%22%3E%5Cn%20%20%20%20%3Cdiv%20class%3D%5C%22csl-left-margin%5C%22%20style%3D%5C%22float%3A%20left%3B%20padding-right%3A%200.5em%3B%20text-align%3A%20right%3B%20width%3A%201em%3B%5C%22%3E%5B1%5D%3C%5C%2Fdiv%3E%3Cdiv%20class%3D%5C%22csl-right-inline%5C%22%20style%3D%5C%22margin%3A%200%20.4em%200%201.5em%3B%5C%22%3EM.%20Hashida%2C%20S.%20Tanaka%2C%20and%20H.%20Katayose%2C%20%26%23x201C%3BMixtract%3A%20A%20directable%20musical%20expression%20system%2C%26%23x201D%3B%20in%20%3Ci%3E2009%203rd%20International%20Conference%20on%20Affective%20Computing%20and%20Intelligent%20Interaction%20and%20Workshops%3C%5C%2Fi%3E%2C%20Sep.%202009%2C%20pp.%201%26%23x2013%3B6.%20doi%3A%2010.1109%5C%2FACII.2009.5349553.%3C%5C%2Fdiv%3E%5Cn%20%20%3C%5C%2Fdiv%3E%5Cn%3C%5C%2Fdiv%3E%22%2C%22data%22%3A%7B%22itemType%22%3A%22conferencePaper%22%2C%22title%22%3A%22Mixtract%3A%20A%20directable%20musical%20expression%20system%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22M.%22%2C%22lastName%22%3A%22Hashida%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22S.%22%2C%22lastName%22%3A%22Tanaka%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22H.%22%2C%22lastName%22%3A%22Katayose%22%7D%5D%2C%22abstractNote%22%3A%22This%20paper%20describes%20a%20music%20performance%20design%20system%20focusing%20on%20phrasing%2C%20the%20design%20and%20development%20of%20an%20intuitive%20interface%20to%20assist%20music%20performance%20design%20system.%20The%20proposed%20interface%20has%20an%20editor%20to%20control%20the%20parameter%20curves%20of%20%5Cu00bfdynamics%5Cu00bf%20and%20%5Cu00bftempos%5Cu00bf%20of%20hierarchical%20phrase%20structures%2C%20and%20supports%20analysis%20mechanisms%20for%20hierarchical%20phrase%20structures%20that%20lighten%20the%20users%27%20work%20for%20music%20interpretation.%20We%20are%20interested%20in%20how%20a%20system%20can%20assist%20the%20users%20in%20designing%20music%20performances%2C%20but%20not%20to%20develop%20a%20full%20automatic%20system.%20Unlike%20the%20most%20automatic%20performance%20rendering%20systems%20to%20date%2C%20assisting%20the%20process%20of%20music%20interpretation%20and%20to%20convey%20the%20musical%20interpretive%20intent%20to%20the%20system%20are%20focused%20in%20this%20paper.%20The%20advantage%20of%20the%20proposed%20system%20was%20verified%20from%20shortening%20time%20required%20for%20music%20performance%20design.%20The%20proposed%20system%20is%20more%20beneficial%20from%20the%20viewpoint%20that%20it%20can%20be%20a%20platform%20to%20test%20various%20possibilities%20of%20phrasing%20expression.%22%2C%22proceedingsTitle%22%3A%222009%203rd%20International%20Conference%20on%20Affective%20Computing%20and%20Intelligent%20Interaction%20and%20Workshops%22%2C%22conferenceName%22%3A%222009%203rd%20International%20Conference%20on%20Affective%20Computing%20and%20Intelligent%20Interaction%20and%20Workshops%22%2C%22date%22%3A%22Sep.%202009%22%2C%22eventPlace%22%3A%22%22%2C%22DOI%22%3A%2210.1109%5C%2FACII.2009.5349553%22%2C%22ISBN%22%3A%22%22%2C%22citationKey%22%3A%22%22%2C%22url%22%3A%22%22%2C%22ISSN%22%3A%22%22%2C%22language%22%3A%22%22%2C%22collections%22%3A%5B%2286JQZ5DR%22%2C%22FIB6M7GA%22%5D%2C%22dateModified%22%3A%222019-04-20T11%3A12%3A21Z%22%7D%7D%2C%7B%22key%22%3A%22JJ3GQ24H%22%2C%22library%22%3A%7B%22id%22%3A5289163%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22%5Cu7530%5Cu4e2d%20%5Cu99ff%5Cu4e8c%20et%20al.%22%2C%22parsedDate%22%3A%222009-07-22%22%2C%22numChildren%22%3A2%7D%2C%22bib%22%3A%22%3Cdiv%20class%3D%5C%22csl-bib-body%5C%22%20style%3D%5C%22line-height%3A%201.35%3B%20%5C%22%3E%5Cn%20%3Cdiv%20class%3D%5C%22csl-entry%5C%22%20style%3D%5C%22clear%3A%20left%3B%20%5C%22%3E%5Cn%20%3Cdiv%20class%3D%5C%22csl-left-margin%5C%22%20style%3D%5C%22float%3A%20left%3B%20padding-right%3A%200.5em%3B%20text-align%3A%20right%3B%20width%3A%201em%3B%5C%22%3E%5B1%5D%3C%5C%2Fdiv%3E%3Cdiv%20class%3D%5C%22csl-right-inline%5C%22%20style%3D%5C%22margin%3A%200%20.4em%200%201.5em%3B%5C%22%3E%5Cu7530%5Cu4e2d%20%5Cu99ff%5Cu4e8c%2C%20%5Cu6a4b%5Cu7530%20%5Cu5149%5Cu4ee3%2C%20%5Cu7247%5Cu5bc4%20%5Cu6674%5Cu5f18%2C%20%5C%22%3Ca%20href%3D%27https%3A%5C%2F%5C%2Fipsj.ixsq.nii.ac.jp%5C%2Fej%5C%2Findex.php%3Factive_action%3Drepository_view_main_item_detail%26page_id%3D13%26block_id%3D8%26item_id%3D62637%26item_no%3D1%27%3E%5Cu6f14%5Cu594f%5Cu8868%5Cu60c5%5Cu4ed8%5Cu3051%5Cu30b7%5Cu30b9%5Cu30c6%5Cu30e0%5Cu306e%5Cu305f%5Cu3081%5Cu306e%5Cu30e6%5Cu30fc%5Cu30b6%5Cu4e3b%5Cu5c0e%5Cu578b%5Cu97f3%5Cu697d%5Cu69cb%5Cu9020%5Cu5206%5Cu6790%3C%5C%2Fa%3E%2C%5C%22%20%3Ci%3E%5Cu7814%5Cu7a76%5Cu5831%5Cu544a%5Cu97f3%5Cu697d%5Cu60c5%5Cu5831%5Cu79d1%5Cu5b66%5Cuff08MUS%5Cuff09%3C%5C%2Fi%3E%2C%20vol.%202009-MUS-81%2C%20no.%2023%2C%20pp.%201%5Cu20137%2C%20Jul.%202009%2C%20Accessed%3A%20Dec.%2005%2C%202018.%20%5BOnline%5D.%20Available%3A%20%3C%5C%2Fdiv%3E%5Cn%20%3C%5C%2Fdiv%3E%5Cn%3C%5C%2Fdiv%3E%22%2C%22data%22%3A%7B%22itemType%22%3A%22journalArticle%22%2C%22title%22%3A%22%5Cu6f14%5Cu594f%5Cu8868%5Cu60c5%5Cu4ed8%5Cu3051%5Cu30b7%5Cu30b9%5Cu30c6%5Cu30e0%5Cu306e%5Cu305f%5Cu3081%5Cu306e%5Cu30e6%5Cu30fc%5Cu30b6%5Cu4e3b%5Cu5c0e%5Cu578b%5Cu97f3%5Cu697d%5Cu69cb%5Cu9020%5Cu5206%5Cu6790%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22name%22%3A%22%5Cu7530%5Cu4e2d%20%5Cu99ff%5Cu4e8c%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22name%22%3A%22%5Cu6a4b%5Cu7530%20%5Cu5149%5Cu4ee3%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22name%22%3A%22%5Cu7247%5Cu5bc4%20%5Cu6674%5Cu5f18%22%7D%5D%2C%22abstractNote%22%3A%22%5Cu60c5%5Cu5831%5Cu5b66%5Cu5e83%5Cu5834%20%5Cu60c5%5Cu5831%5Cu51e6%5Cu7406%5Cu5b66%5Cu4f1a%5Cu96fb%5Cu5b50%5Cu56f3%5Cu66f8%5Cu9928%22%2C%22date%22%3A%222009%5C%2F07%5C%2F22%22%2C%22section%22%3A%22%22%2C%22partNumber%22%3A%22%22%2C%22partTitle%22%3A%22%22%2C%22DOI%22%3A%22%22%2C%22citationKey%22%3A%22%22%2C%22url%22%3A%22https%3A%5C%2F%5C%2Fipsj.ixsq.nii.ac.jp%5C%2Fej%5C%2Findex.php%3Factive_action%3Drepository_view_main_item_detail%26page_id%3D13%26block_id%3D8%26item_id%3D62637%26item_no%3D1%22%2C%22PMID%22%3A%22%22%2C%22PMCID%22%3A%22%22%2C%22ISSN%22%3A%22%22%2C%22language%22%3A%22ja%22%2C%22collections%22%3A%5B%2286JQZ5DR%22%2C%223W3TMNBQ%22%5D%2C%22dateModified%22%3A%222019-04-20T11%3A14%3A59Z%22%7D%7D%2C%7B%22key%22%3A%224SCKM3GL%22%2C%22library%22%3A%7B%22id%22%3A5289163%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22%5Cu7530%5Cu4e2d%20%5Cu99ff%5Cu4e8c%20et%20al.%22%2C%22parsedDate%22%3A%222009-03-10%22%2C%22numChildren%22%3A2%7D%2C%22bib%22%3A%22%3Cdiv%20class%3D%5C%22csl-bib-body%5C%22%20style%3D%5C%22line-height%3A%201.35%3B%20%5C%22%3E%5Cn%20%3Cdiv%20class%3D%5C%22csl-entry%5C%22%20style%3D%5C%22clear%3A%20left%3B%20%5C%22%3E%5Cn%20%3Cdiv%20class%3D%5C%22csl-left-margin%5C%22%20style%3D%5C%22float%3A%20left%3B%20padding-right%3A%200.5em%3B%20text-align%3A%20right%3B%20width%3A%201em%3B%5C%22%3E%5B1%5D%3C%5C%2Fdiv%3E%3Cdiv%20class%3D%5C%22csl-right-inline%5C%22%20style%3D%5C%22margin%3A%200%20.4em%200%201.5em%3B%5C%22%3E%5Cu7530%5Cu4e2d%20%5Cu99ff%5Cu4e8c%2C%20%5Cu6a4b%5Cu7530%20%5Cu5149%5Cu4ee3%2C%20%5Cu7247%5Cu5bc4%20%5Cu6674%5Cu5f18%2C%20%5C%22%3Ca%20href%3D%27https%3A%5C%2F%5C%2Fipsj.ixsq.nii.ac.jp%5C%2Fej%5C%2Findex.php%3Factive_action%3Drepository_view_main_item_detail%26page_id%3D13%26block_id%3D8%26item_id%3D138761%26item_no%3D1%27%3E%5Cu30e6%5Cu30fc%5Cu30b6%5Cu3068%5Cu306e%5Cu30a4%5Cu30f3%5Cu30bf%5Cu30e9%5Cu30af%5Cu30b7%5Cu30e7%5Cu30f3%5Cu30d7%5Cu30ed%5Cu30bb%5Cu30b9%5Cu3092%5Cu524d%5Cu63d0%5Cu3068%5Cu3057%5Cu305f%5Cu697d%5Cu66f2%5Cu69cb%5Cu9020%5Cu5206%5Cu6790%3C%5C%2Fa%3E%2C%5C%22%20%5Cu5168%5Cu56fd%5Cu5927%5Cu4f1a%5Cu8b1b%5Cu6f14%5Cu8ad6%5Cu6587%5Cu96c6%2C%20vol.%20%5Cu7b2c71%5Cu56de%2C%20no.%20%5Cu4eba%5Cu5de5%5Cu77e5%5Cu80fd%5Cu3068%5Cu8a8d%5Cu77e5%5Cu79d1%5Cu5b66%2C%20pp.%20225%5Cu2013226%2C%20Mar.%202009%2C%20Accessed%3A%20Mar.%2015%2C%202019.%20%5BOnline%5D.%20Available%3A%20%3C%5C%2Fdiv%3E%5Cn%20%3C%5C%2Fdiv%3E%5Cn%3C%5C%2Fdiv%3E%22%2C%22data%22%3A%7B%22itemType%22%3A%22journalArticle%22%2C%22title%22%3A%22%5Cu30e6%5Cu30fc%5Cu30b6%5Cu3068%5Cu306e%5Cu30a4%5Cu30f3%5Cu30bf%5Cu30e9%5Cu30af%5Cu30b7%5Cu30e7%5Cu30f3%5Cu30d7%5Cu30ed%5Cu30bb%5Cu30b9%5Cu3092%5Cu524d%5Cu63d0%5Cu3068%5Cu3057%5Cu305f%5Cu697d%5Cu66f2%5Cu69cb%5Cu9020%5Cu5206%5Cu6790%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22name%22%3A%22%5Cu7530%5Cu4e2d%20%5Cu99ff%5Cu4e8c%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22name%22%3A%22%5Cu6a4b%5Cu7530%20%5Cu5149%5Cu4ee3%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22name%22%3A%22%5Cu7247%5Cu5bc4%20%5Cu6674%5Cu5f18%22%7D%5D%2C%22abstractNote%22%3A%22%5Cu60c5%5Cu5831%5Cu5b66%5Cu5e83%5Cu5834%20%5Cu60c5%5Cu5831%5Cu51e6%5Cu7406%5Cu5b66%5Cu4f1a%5Cu96fb%5Cu5b50%5Cu56f3%5Cu66f8%5Cu9928%22%2C%22date%22%3A%222009%5C%2F03%5C%2F10%22%2C%22section%22%3A%22%22%2C%22partNumber%22%3A%22%22%2C%22partTitle%22%3A%22%22%2C%22DOI%22%3A%22%22%2C%22citationKey%22%3A%22%22%2C%22url%22%3A%22https%3A%5C%2F%5C%2Fipsj.ixsq.nii.ac.jp%5C%2Fej%5C%2Findex.php%3Factive_action%3Drepository_view_main_item_detail%26page_id%3D13%26block_id%3D8%26item_id%3D138761%26item_no%3D1%22%2C%22PMID%22%3A%22%22%2C%22PMCID%22%3A%22%22%2C%22ISSN%22%3A%22%22%2C%22language%22%3A%22ja%22%2C%22collections%22%3A%5B%223W3TMNBQ%22%5D%2C%22dateModified%22%3A%222020-03-12T03%3A26%3A21Z%22%7D%7D%2C%7B%22key%22%3A%2278NQNGRY%22%2C%22library%22%3A%7B%22id%22%3A5289163%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22%5Cu6a4b%5Cu7530%20and%20%5Cu7247%5Cu5bc4%22%2C%22parsedDate%22%3A%222009%22%2C%22numChildren%22%3A0%7D%2C%22bib%22%3A%22%3Cdiv%20class%3D%5C%22csl-bib-body%5C%22%20style%3D%5C%22line-height%3A%201.35%3B%20%5C%22%3E%5Cn%20%20%3Cdiv%20class%3D%5C%22csl-entry%5C%22%20style%3D%5C%22clear%3A%20left%3B%20%5C%22%3E%5Cn%20%20%20%20%3Cdiv%20class%3D%5C%22csl-left-margin%5C%22%20style%3D%5C%22float%3A%20left%3B%20padding-right%3A%200.5em%3B%20text-align%3A%20right%3B%20width%3A%201em%3B%5C%22%3E%5B1%5D%3C%5C%2Fdiv%3E%3Cdiv%20class%3D%5C%22csl-right-inline%5C%22%20style%3D%5C%22margin%3A%200%20.4em%200%201.5em%3B%5C%22%3E%26%23x6A4B%3B%26%23x7530%3B%26%23x5149%3B%26%23x4EE3%3B%20and%20%26%23x7247%3B%26%23x5BC4%3B%26%23x6674%3B%26%23x5F18%3B%2C%20%26%23x201C%3BMixtract%3A%20%26%23x30E6%3B%26%23x30FC%3B%26%23x30B6%3B%26%23x306E%3B%26%23x610F%3B%26%23x56F3%3B%26%23x306B%3B%26%23x5FDC%3B%26%23x3048%3B%26%23x308B%3B%26%23x6F14%3B%26%23x594F%3B%26%23x8868%3B%26%23x73FE%3B%26%23x30C7%3B%26%23x30B6%3B%26%23x30A4%3B%26%23x30F3%3B%26%23x652F%3B%26%23x63F4%3B%26%23x74B0%3B%26%23x5883%3B%2C%26%23x201D%3B%20presented%20at%20the%20%26%23x7B2C%3B17%26%23x56DE%3B%26%23x5927%3B%26%23x962A%3B%26%23x5927%3B%26%23x5B66%3B%26%23x4FDD%3B%26%23x5065%3B%26%23x30BB%3B%26%23x30F3%3B%26%23x30BF%3B%26%23x30FC%3B%20%26%23x5065%3B%26%23x5EB7%3B%26%23x79D1%3B%26%23x5B66%3B%26%23x30D5%3B%26%23x30A9%3B%26%23x30FC%3B%26%23x30E9%3B%26%23x30E0%3B%26%23x300C%3B%26%23x97F3%3B%26%23x697D%3B%26%23x3068%3B%26%23x30A6%3B%26%23x30A7%3B%26%23x30EB%3B%26%23x30CD%3B%26%23x30B9%3B%26%23x306E%3B%26%23x5B66%3B%26%23x969B%3B%26%23x7684%3B%26%23x878D%3B%26%23x5408%3B%26%23x300D%3B%2C%202009%2C%20pp.%2036%26%23x2013%3B37.%3C%5C%2Fdiv%3E%5Cn%20%20%3C%5C%2Fdiv%3E%5Cn%3C%5C%2Fdiv%3E%22%2C%22data%22%3A%7B%22itemType%22%3A%22conferencePaper%22%2C%22title%22%3A%22Mixtract%3A%20%5Cu30e6%5Cu30fc%5Cu30b6%5Cu306e%5Cu610f%5Cu56f3%5Cu306b%5Cu5fdc%5Cu3048%5Cu308b%5Cu6f14%5Cu594f%5Cu8868%5Cu73fe%5Cu30c7%5Cu30b6%5Cu30a4%5Cu30f3%5Cu652f%5Cu63f4%5Cu74b0%5Cu5883%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22%5Cu5149%5Cu4ee3%22%2C%22lastName%22%3A%22%5Cu6a4b%5Cu7530%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22%5Cu6674%5Cu5f18%22%2C%22lastName%22%3A%22%5Cu7247%5Cu5bc4%22%7D%5D%2C%22abstractNote%22%3A%22%22%2C%22proceedingsTitle%22%3A%22%22%2C%22conferenceName%22%3A%22%5Cu7b2c17%5Cu56de%5Cu5927%5Cu962a%5Cu5927%5Cu5b66%5Cu4fdd%5Cu5065%5Cu30bb%5Cu30f3%5Cu30bf%5Cu30fc%20%5Cu5065%5Cu5eb7%5Cu79d1%5Cu5b66%5Cu30d5%5Cu30a9%5Cu30fc%5Cu30e9%5Cu30e0%5Cu300c%5Cu97f3%5Cu697d%5Cu3068%5Cu30a6%5Cu30a7%5Cu30eb%5Cu30cd%5Cu30b9%5Cu306e%5Cu5b66%5Cu969b%5Cu7684%5Cu878d%5Cu5408%5Cu300d%22%2C%22date%22%3A%222009%22%2C%22eventPlace%22%3A%22%22%2C%22DOI%22%3A%22%22%2C%22ISBN%22%3A%22%22%2C%22citationKey%22%3A%22%22%2C%22url%22%3A%22%22%2C%22ISSN%22%3A%22%22%2C%22language%22%3A%22%22%2C%22collections%22%3A%5B%2286JQZ5DR%22%5D%2C%22dateModified%22%3A%222020-03-12T03%3A11%3A09Z%22%7D%7D%2C%7B%22key%22%3A%22DF4BZDGC%22%2C%22library%22%3A%7B%22id%22%3A5289163%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Hashida%20et%20al.%22%2C%22parsedDate%22%3A%222008%22%2C%22numChildren%22%3A0%7D%2C%22bib%22%3A%22%3Cdiv%20class%3D%5C%22csl-bib-body%5C%22%20style%3D%5C%22line-height%3A%201.35%3B%20%5C%22%3E%5Cn%20%20%3Cdiv%20class%3D%5C%22csl-entry%5C%22%20style%3D%5C%22clear%3A%20left%3B%20%5C%22%3E%5Cn%20%20%20%20%3Cdiv%20class%3D%5C%22csl-left-margin%5C%22%20style%3D%5C%22float%3A%20left%3B%20padding-right%3A%200.5em%3B%20text-align%3A%20right%3B%20width%3A%201em%3B%5C%22%3E%5B1%5D%3C%5C%2Fdiv%3E%3Cdiv%20class%3D%5C%22csl-right-inline%5C%22%20style%3D%5C%22margin%3A%200%20.4em%200%201.5em%3B%5C%22%3EM.%20Hashida%2C%20Y.%20Ito%2C%20and%20H.%20Katayose%2C%20%26%23x201C%3BA%20Directable%20Performance%20Rendering%20System%3A%20Itopul.%2C%26%23x201D%3B%20in%20%3Ci%3ENIME%3C%5C%2Fi%3E%2C%202008%2C%20pp.%20277%26%23x2013%3B280.%3C%5C%2Fdiv%3E%5Cn%20%20%3C%5C%2Fdiv%3E%5Cn%3C%5C%2Fdiv%3E%22%2C%22data%22%3A%7B%22itemType%22%3A%22conferencePaper%22%2C%22title%22%3A%22A%20Directable%20Performance%20Rendering%20System%3A%20Itopul.%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Mitsuyo%22%2C%22lastName%22%3A%22Hashida%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Yosuke%22%2C%22lastName%22%3A%22Ito%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Haruhiro%22%2C%22lastName%22%3A%22Katayose%22%7D%5D%2C%22abstractNote%22%3A%22%22%2C%22proceedingsTitle%22%3A%22NIME%22%2C%22conferenceName%22%3A%22%22%2C%22date%22%3A%222008%22%2C%22eventPlace%22%3A%22%22%2C%22DOI%22%3A%22%22%2C%22ISBN%22%3A%22%22%2C%22citationKey%22%3A%22%22%2C%22url%22%3A%22%22%2C%22ISSN%22%3A%22%22%2C%22language%22%3A%22%22%2C%22collections%22%3A%5B%2286JQZ5DR%22%2C%223W3TMNBQ%22%5D%2C%22dateModified%22%3A%222020-03-12T03%3A27%3A33Z%22%7D%7D%2C%7B%22key%22%3A%228KI3ZPR9%22%2C%22library%22%3A%7B%22id%22%3A5289163%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22%5Cu4f0a%5Cu85e4%5Cu6d0b%5Cu4ecb%20et%20al.%22%2C%22parsedDate%22%3A%222007-12-15%22%2C%22numChildren%22%3A2%7D%2C%22bib%22%3A%22%3Cdiv%20class%3D%5C%22csl-bib-body%5C%22%20style%3D%5C%22line-height%3A%201.35%3B%20%5C%22%3E%5Cn%20%3Cdiv%20class%3D%5C%22csl-entry%5C%22%20style%3D%5C%22clear%3A%20left%3B%20%5C%22%3E%5Cn%20%3Cdiv%20class%3D%5C%22csl-left-margin%5C%22%20style%3D%5C%22float%3A%20left%3B%20padding-right%3A%200.5em%3B%20text-align%3A%20right%3B%20width%3A%201em%3B%5C%22%3E%5B1%5D%3C%5C%2Fdiv%3E%3Cdiv%20class%3D%5C%22csl-right-inline%5C%22%20style%3D%5C%22margin%3A%200%20.4em%200%201.5em%3B%5C%22%3E%5Cu4f0a%5Cu85e4%5Cu6d0b%5Cu4ecb%2C%20%5Cu6a4b%5Cu7530%20%5Cu5149%5Cu4ee3%2C%20%5Cu7247%5Cu5bc4%20%5Cu6674%5Cu5f18%2C%20%5C%22%3Ca%20href%3D%27https%3A%5C%2F%5C%2Fipsj.ixsq.nii.ac.jp%5C%2Fej%5C%2Findex.php%3Factive_action%3Drepository_view_main_item_detail%26page_id%3D13%26block_id%3D8%26item_id%3D55741%26item_no%3D1%27%3E%5Cu8907%5Cu6570%5Cu306e%5Cu751f%5Cu6210%5Cu30d7%5Cu30ed%5Cu30bb%5Cu30b9%5Cu304c%5Cu5236%5Cu5fa1%5Cu53ef%5Cu80fd%5Cu306a%5Cu6f14%5Cu594f%5Cu751f%5Cu6210%5Cu30b7%5Cu30b9%5Cu30c6%5Cu30e0%5Cu300cItopul%5Cu300d%3C%5C%2Fa%3E%2C%5C%22%20%3Ci%3E%5Cu60c5%5Cu5831%5Cu51e6%5Cu7406%5Cu5b66%5Cu4f1a%5Cu7814%5Cu7a76%5Cu5831%5Cu544a%5Cu97f3%5Cu697d%5Cu60c5%5Cu5831%5Cu79d1%5Cu5b66%5Cuff08MUS%5Cuff09%3C%5C%2Fi%3E%2C%20vol.%202007%2C%20no.%20127%282007-MUS-073%29%2C%20pp.%2045%5Cu201350%2C%20Dec.%202007%2C%20Accessed%3A%20Nov.%2009%2C%202018.%20%5BOnline%5D.%20Available%3A%20%3C%5C%2Fdiv%3E%5Cn%20%3C%5C%2Fdiv%3E%5Cn%3C%5C%2Fdiv%3E%22%2C%22data%22%3A%7B%22itemType%22%3A%22journalArticle%22%2C%22title%22%3A%22%5Cu8907%5Cu6570%5Cu306e%5Cu751f%5Cu6210%5Cu30d7%5Cu30ed%5Cu30bb%5Cu30b9%5Cu304c%5Cu5236%5Cu5fa1%5Cu53ef%5Cu80fd%5Cu306a%5Cu6f14%5Cu594f%5Cu751f%5Cu6210%5Cu30b7%5Cu30b9%5Cu30c6%5Cu30e0%5Cu300cItopul%5Cu300d%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22name%22%3A%22%5Cu4f0a%5Cu85e4%5Cu6d0b%5Cu4ecb%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22name%22%3A%22%5Cu6a4b%5Cu7530%20%5Cu5149%5Cu4ee3%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22name%22%3A%22%5Cu7247%5Cu5bc4%20%5Cu6674%5Cu5f18%22%7D%5D%2C%22abstractNote%22%3A%22%5Cu60c5%5Cu5831%5Cu5b66%5Cu5e83%5Cu5834%20%5Cu60c5%5Cu5831%5Cu51e6%5Cu7406%5Cu5b66%5Cu4f1a%5Cu96fb%5Cu5b50%5Cu56f3%5Cu66f8%5Cu9928%22%2C%22date%22%3A%222007%5C%2F12%5C%2F15%22%2C%22section%22%3A%22%22%2C%22partNumber%22%3A%22%22%2C%22partTitle%22%3A%22%22%2C%22DOI%22%3A%22%22%2C%22citationKey%22%3A%22%22%2C%22url%22%3A%22https%3A%5C%2F%5C%2Fipsj.ixsq.nii.ac.jp%5C%2Fej%5C%2Findex.php%3Factive_action%3Drepository_view_main_item_detail%26page_id%3D13%26block_id%3D8%26item_id%3D55741%26item_no%3D1%22%2C%22PMID%22%3A%22%22%2C%22PMCID%22%3A%22%22%2C%22ISSN%22%3A%22%22%2C%22language%22%3A%22ja%22%2C%22collections%22%3A%5B%2286JQZ5DR%22%2C%223W3TMNBQ%22%5D%2C%22dateModified%22%3A%222020-03-12T03%3A27%3A39Z%22%7D%7D%2C%7B%22key%22%3A%22WKU7ZSFZ%22%2C%22library%22%3A%7B%22id%22%3A5289163%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22%5Cu6a4b%5Cu7530%20%5Cu5149%5Cu4ee3%20et%20al.%22%2C%22parsedDate%22%3A%222007-01-15%22%2C%22numChildren%22%3A2%7D%2C%22bib%22%3A%22%3Cdiv%20class%3D%5C%22csl-bib-body%5C%22%20style%3D%5C%22line-height%3A%201.35%3B%20%5C%22%3E%5Cn%20%3Cdiv%20class%3D%5C%22csl-entry%5C%22%20style%3D%5C%22clear%3A%20left%3B%20%5C%22%3E%5Cn%20%3Cdiv%20class%3D%5C%22csl-left-margin%5C%22%20style%3D%5C%22float%3A%20left%3B%20padding-right%3A%200.5em%3B%20text-align%3A%20right%3B%20width%3A%201em%3B%5C%22%3E%5B1%5D%3C%5C%2Fdiv%3E%3Cdiv%20class%3D%5C%22csl-right-inline%5C%22%20style%3D%5C%22margin%3A%200%20.4em%200%201.5em%3B%5C%22%3E%5Cu6a4b%5Cu7530%20%5Cu5149%5Cu4ee3%2C%20%5Cu9577%5Cu7530%20%5Cu5178%5Cu5b50%2C%20%5Cu6cb3%5Cu539f%20%5Cu82f1%5Cu7d00%2C%20%5Cu7247%5Cu5bc4%20%5Cu6674%5Cu5f18%2C%20%5C%22%3Ca%20href%3D%27https%3A%5C%2F%5C%2Fipsj.ixsq.nii.ac.jp%5C%2Fej%5C%2Findex.php%3Factive_action%3Drepository_view_main_item_detail%26page_id%3D13%26block_id%3D8%26item_id%3D10102%26item_no%3D1%27%3E%5Cu8907%5Cu6570%5Cu65cb%5Cu5f8b%5Cu97f3%5Cu697d%5Cu306b%5Cu5bfe%5Cu3059%5Cu308b%5Cu6f14%5Cu594f%5Cu8868%5Cu60c5%5Cu4ed8%5Cu3051%5Cu30e2%5Cu30c7%5Cu30eb%5Cu306e%5Cu69cb%5Cu7bc9%3C%5C%2Fa%3E%2C%5C%22%20%5Cu60c5%5Cu5831%5Cu51e6%5Cu7406%5Cu5b66%5Cu4f1a%5Cu8ad6%5Cu6587%5Cu8a8c%2C%20vol.%2048%2C%20no.%201%2C%20pp.%20248%5Cu2013257%2C%20Jan.%202007%2C%20Accessed%3A%20Nov.%2009%2C%202018.%20%5BOnline%5D.%20Available%3A%20%3C%5C%2Fdiv%3E%5Cn%20%3C%5C%2Fdiv%3E%5Cn%3C%5C%2Fdiv%3E%22%2C%22data%22%3A%7B%22itemType%22%3A%22journalArticle%22%2C%22title%22%3A%22%5Cu8907%5Cu6570%5Cu65cb%5Cu5f8b%5Cu97f3%5Cu697d%5Cu306b%5Cu5bfe%5Cu3059%5Cu308b%5Cu6f14%5Cu594f%5Cu8868%5Cu60c5%5Cu4ed8%5Cu3051%5Cu30e2%5Cu30c7%5Cu30eb%5Cu306e%5Cu69cb%5Cu7bc9%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22name%22%3A%22%5Cu6a4b%5Cu7530%20%5Cu5149%5Cu4ee3%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22name%22%3A%22%5Cu9577%5Cu7530%20%5Cu5178%5Cu5b50%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22name%22%3A%22%5Cu6cb3%5Cu539f%20%5Cu82f1%5Cu7d00%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22name%22%3A%22%5Cu7247%5Cu5bc4%20%5Cu6674%5Cu5f18%22%7D%5D%2C%22abstractNote%22%3A%22%5Cu60c5%5Cu5831%5Cu5b66%5Cu5e83%5Cu5834%20%5Cu60c5%5Cu5831%5Cu51e6%5Cu7406%5Cu5b66%5Cu4f1a%5Cu96fb%5Cu5b50%5Cu56f3%5Cu66f8%5Cu9928%22%2C%22date%22%3A%222007%5C%2F01%5C%2F15%22%2C%22section%22%3A%22%22%2C%22partNumber%22%3A%22%22%2C%22partTitle%22%3A%22%22%2C%22DOI%22%3A%22%22%2C%22citationKey%22%3A%22%22%2C%22url%22%3A%22https%3A%5C%2F%5C%2Fipsj.ixsq.nii.ac.jp%5C%2Fej%5C%2Findex.php%3Factive_action%3Drepository_view_main_item_detail%26page_id%3D13%26block_id%3D8%26item_id%3D10102%26item_no%3D1%22%2C%22PMID%22%3A%22%22%2C%22PMCID%22%3A%22%22%2C%22ISSN%22%3A%221882-7764%22%2C%22language%22%3A%22ja%22%2C%22collections%22%3A%5B%2286JQZ5DR%22%2C%223W3TMNBQ%22%5D%2C%22dateModified%22%3A%222020-03-12T03%3A26%3A42Z%22%7D%7D%2C%7B%22key%22%3A%22N2MC2XAI%22%2C%22library%22%3A%7B%22id%22%3A5289163%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Hashida%20et%20al.%22%2C%22parsedDate%22%3A%222006%22%2C%22numChildren%22%3A0%7D%2C%22bib%22%3A%22%3Cdiv%20class%3D%5C%22csl-bib-body%5C%22%20style%3D%5C%22line-height%3A%201.35%3B%20%5C%22%3E%5Cn%20%3Cdiv%20class%3D%5C%22csl-entry%5C%22%20style%3D%5C%22clear%3A%20left%3B%20%5C%22%3E%5Cn%20%3Cdiv%20class%3D%5C%22csl-left-margin%5C%22%20style%3D%5C%22float%3A%20left%3B%20padding-right%3A%200.5em%3B%20text-align%3A%20right%3B%20width%3A%201em%3B%5C%22%3E%5B1%5D%3C%5C%2Fdiv%3E%3Cdiv%20class%3D%5C%22csl-right-inline%5C%22%20style%3D%5C%22margin%3A%200%20.4em%200%201.5em%3B%5C%22%3EM.%20Hashida%2C%20N.%20Nagata%2C%20and%20H.%20Katayose%2C%20%5C%22%3Ca%20href%3D%27http%3A%5C%2F%5C%2Fwww.escom-icmpc-2006.org%5C%2Fpdfs%5C%2F467.pdf%27%3EPop-E%3A%20A%20performance%20rendering%20system%20for%20the%20ensemble%20music%20that%20considered%20group%20expression%3C%5C%2Fa%3E%2C%5C%22%20in%20%3Ci%3EProc.%20of%20International%20Conference%20on%20Music%20Perception%20and%20Cognition%20%28ICMPC%29%3C%5C%2Fi%3E%2C%202006%2C%20pp.%20526%5Cu2013534.%20%5BOnline%5D.%20Available%3A%20%3C%5C%2Fdiv%3E%5Cn%20%3C%5C%2Fdiv%3E%5Cn%3C%5C%2Fdiv%3E%22%2C%22data%22%3A%7B%22itemType%22%3A%22conferencePaper%22%2C%22title%22%3A%22Pop-E%3A%20A%20performance%20rendering%20system%20for%20the%20ensemble%20music%20that%20considered%20group%20expression%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Mitsuyo%22%2C%22lastName%22%3A%22Hashida%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Noriko%22%2C%22lastName%22%3A%22Nagata%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Haruhiro%22%2C%22lastName%22%3A%22Katayose%22%7D%5D%2C%22abstractNote%22%3A%22This%20paper%20describes%20design%20and%20systematization%20of%20a%20music%20performance%20rendering%20model%20and%20some%20evaluations.%20Musical%20performance%20rendering%20has%20been%20one%20of%20the%20hottest%20themes%20in%20music%20study%20related%20to%20artificial%20intelligence.%20For%20the%20last%20two%20decades%2C%20quality%20of%20musical%20performances%20rendered%20by%20computers%20has%20been%20much%20improved.%20Some%20performances%20can%20be%20compared%20with%20skilled%20amateur%20musicians.%20But%20still%2C%20there%20remain%20problems%20to%20be%20solved%2C%20especially%20on%201%29%20automatic%20analysis%20of%20musical%20structure%2C%20and%202%29%20natural%20expression%20of%20ensemble%20%28polyphonic%29%20music.%20We%20have%20been%20engaged%20in%20research%20in%20designing%20computational%20models%20to%20cope%20with%20these%20problems%2C%20and%20have%20proposed%20some%20systems.%20In%20this%20paper%2C%20we%20are%20going%20to%20show%20a%20rule-based%20performance%20rendering%20architecture%20called%20Pop-E%2C%20in%20which%20natural%20expression%20of%20polyphonic%20music%20is%20focused%20on.%20Pop-E%20generates%20an%20expressive%20performance%20by%20applying%20rules%20including%20those%20for%20expressing%20groups%20and%20those%20for%20prolonging%20several%20notes%2C%20individually%20to%20each%20voice.%20Different%20from%20other%20performance%20rendering%20systems%2C%20this%20method%20contributes%20to%20gain%20expressiveness%20of%20all%20of%20melodic%20parts.%20To%20the%20contrary%2C%20we%20have%20to%20provide%20functions%20to%20manage%20time%20transition%20of%20each%20part.%20In%20music%20performance%2C%20if%20the%20specific%20notes%20of%20each%20voice%20synchronize%20at%20certain%20points%2C%20other%20parts%20should%20be%20given%20priority%20of%20their%20own%20expression.%20Based%20on%20this%20idea%2C%20we%20formulated%20an%20effective%20way%20to%20find%20the%20synchronization%20points%20using%20group%20structures%20and%20prolongation%20given%20by%20a%20user.%20As%20for%20the%20adjustment%20between%20adjacent%20synchronization%20points%2C%20we%20adopted%20a%20time-wrapping%20procedure%2C%20which%20rescales%20the%20total%20duration%20of%20the%20non-attention%20part%20maintaining%20the%20ratio%20of%20occupied%20length%20of%20each%20note%2C%20as%20it%20may%20fit%20to%20the%20attention%20part%20which%20is%20given%20by%20the%20user.%20One%20of%20the%20characteristic%20rules%20of%20Pop-E%20is%20that%20to%20prolong%20notes%20at%20transit%20of%20an%20attention%20parts%20among%20voices.%20Introduction%20of%20this%20rule%20contributed%20in%20improvement%20of%20performance%20rendering%20of%20the%20of%20Romantic%20school%20music.%20A%20performance%20rendered%20based%20on%20Pop-E%20won%20the%20Rencon%20Award%20at%20NIME-Rencon%20%28Performance%20Rendering%20Contest%20held%20at%20NIME04%2C%20Hamamatsu.%29%20In%20this%20full%20paper%2C%20we%20would%20like%20to%20describe%20evaluation%20of%20the%20model%2C%20from%20the%20points%20of%20productivity%20improvement%20and%20ability%20to%20describe%20plural%20performances%20of%20virtuosi.%22%2C%22proceedingsTitle%22%3A%22Proc.%20of%20International%20Conference%20on%20Music%20Perception%20and%20Cognition%20%28ICMPC%29%22%2C%22conferenceName%22%3A%22%22%2C%22date%22%3A%222006%22%2C%22eventPlace%22%3A%22%22%2C%22DOI%22%3A%22%22%2C%22ISBN%22%3A%22%22%2C%22citationKey%22%3A%22%22%2C%22url%22%3A%22http%3A%5C%2F%5C%2Fwww.escom-icmpc-2006.org%5C%2Fpdfs%5C%2F467.pdf%22%2C%22ISSN%22%3A%22%22%2C%22language%22%3A%22%22%2C%22collections%22%3A%5B%2286JQZ5DR%22%2C%223W3TMNBQ%22%5D%2C%22dateModified%22%3A%222020-03-12T03%3A27%3A12Z%22%7D%7D%5D%7D
[1]
M. Hashida, S. Tanaka, T. Baba, and H. Katayose, “Mixtract: An Environment Designing Musical Phrase Expression,” in Proceedings of Sound and Music Computing (SMC) 2010, 2010, pp. 21–24.
[1]
M. Hashida, S. Tanaka, and H. Katayose, “Mixtract: A directable musical expression system,” in 2009 3rd International Conference on Affective Computing and Intelligent Interaction and Workshops, Sep. 2009, pp. 1–6. doi: 10.1109/ACII.2009.5349553.
[1]
田中 駿二, 橋田 光代, 片寄 晴弘, "演奏表情付けシステムのためのユーザ主導型音楽構造分析," 研究報告音楽情報科学(MUS), vol. 2009-MUS-81, no. 23, pp. 1–7, Jul. 2009, Accessed: Dec. 05, 2018. [Online]. Available:
[1]
田中 駿二, 橋田 光代, 片寄 晴弘, "ユーザとのインタラクションプロセスを前提とした楽曲構造分析," 全国大会講演論文集, vol. 第71回, no. 人工知能と認知科学, pp. 225–226, Mar. 2009, Accessed: Mar. 15, 2019. [Online]. Available:
[1]
橋田光代 and 片寄晴弘, “Mixtract: ユーザの意図に応える演奏表現デザイン支援環境,” presented at the 第17回大阪大学保健センター 健康科学フォーラム「音楽とウェルネスの学際的融合」, 2009, pp. 36–37.
[1]
M. Hashida, Y. Ito, and H. Katayose, “A Directable Performance Rendering System: Itopul.,” in NIME, 2008, pp. 277–280.
[1]
伊藤洋介, 橋田 光代, 片寄 晴弘, "複数の生成プロセスが制御可能な演奏生成システム「Itopul」," 情報処理学会研究報告音楽情報科学(MUS), vol. 2007, no. 127(2007-MUS-073), pp. 45–50, Dec. 2007, Accessed: Nov. 09, 2018. [Online]. Available:
[1]
橋田 光代, 長田 典子, 河原 英紀, 片寄 晴弘, "複数旋律音楽に対する演奏表情付けモデルの構築," 情報処理学会論文誌, vol. 48, no. 1, pp. 248–257, Jan. 2007, Accessed: Nov. 09, 2018. [Online]. Available:
[1]
M. Hashida, N. Nagata, and H. Katayose, "Pop-E: A performance rendering system for the ensemble music that considered group expression," in Proc. of International Conference on Music Perception and Cognition (ICMPC), 2006, pp. 526–534. [Online]. Available: